Open-Source Instant Transfer of Trillion-Parameter Models Between Training and Inference
Jiadong Guo
Last year I started working on RL infrastructure. The system at the time required going through disk to update inference parameters — as you can imagine, the update speed was abysmal. Inference units competed for disk bandwidth until other parts of the system crashed. That's when I read Lequn's “Explorations in Cross-Machine Instant RL Model Parameter Updates” and was blown away. Since I'm not great at building wheels from scratch (couldn't hand-roll a new RDMA communication library), I figured that mounting existing wheels and contributing to the open-source community was still making a difference.
Six months later, our final results show we can transfer a 512-GPU, 1T Kimi FP8 model in 7 seconds, and a 744B BF16 GLM5 model in 8.5 seconds on H100s with InfiniBand — roughly 7x faster than previous open-source solutions. We support all mainstream open-source models and parallelism configurations on both sides. Note that this 7 seconds includes the entire time from pausing the inference engine to resuming generation — the total RL training stall time.
Core code and usage: Miles P2P Implementation | SGLang Introduction | SGLang-Miles Implementation
Designing the Transfer Logic
Lequn's system design pursues ultimate performance — by implementing a new low-level RDMA transfer library, seeking optimal one-to-one weight-level mappings to adapt transfer strategies between FSDP and inference engines, supporting Qwen3 and Kimi. Our goal was to reuse existing low-level libraries as much as possible, support multiple training backends (Megatron/FSDP), and cover as many open-source models, parallelism, and quantization settings as possible.
The current UpdateWeightFromDistributed implementation relies on NCCL broadcast primitives formed between each PP group's head rank and all inference ranks. On the source side, all nodes first participate in TP and EP dimension all-gathers, producing aggregated weights at each PP rank's head rank. These weights are then converted to HF format. Subsequently, the head rank broadcasts complete HF weights to each engine rank via the update_weight_from_distributed API.
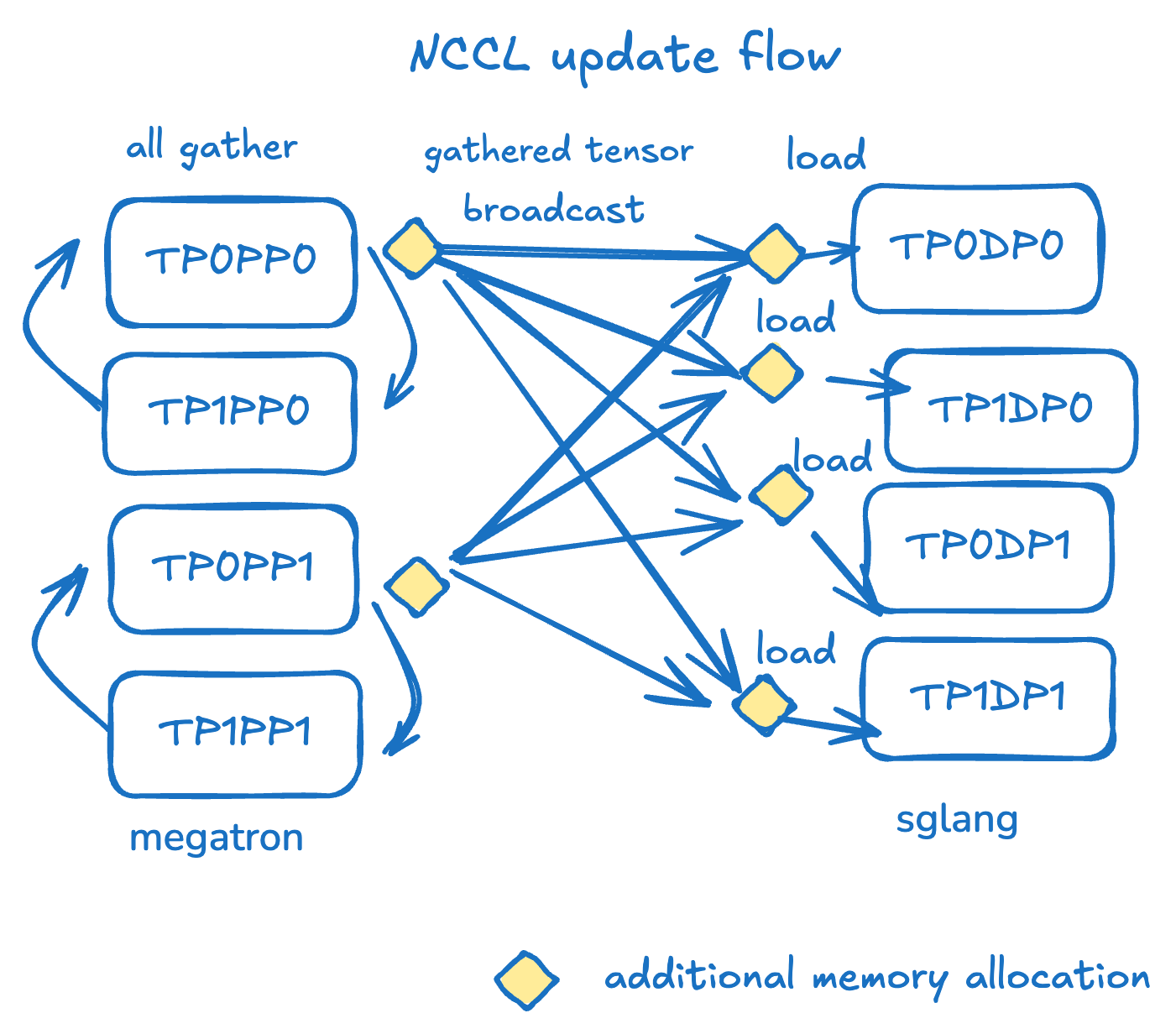
The current NCCL broadcast-based solution has the following problems:
- Redundancy: The same data is sent repeatedly across the network.
- Inactivity: Most training-side ranks are idle during transfer.
- Rigidity: NCCL communication groups cannot be updated once defined.
On the other hand, by using HuggingFace full weights as the sole interface, the specific parallelism modes on both sides can be fully abstracted away.
We then thought of SGLang's remote fork — a mechanism for remote weight loading. Its transport layer uses Transfer Engine to support RDMA communication. Memory/VRAM addresses registered with Transfer Engine can be directly transferred over the network via RDMA, bypassing kernel cache and CPU intermediaries.
Design Proposal 1: Replace NCCL with RDMA
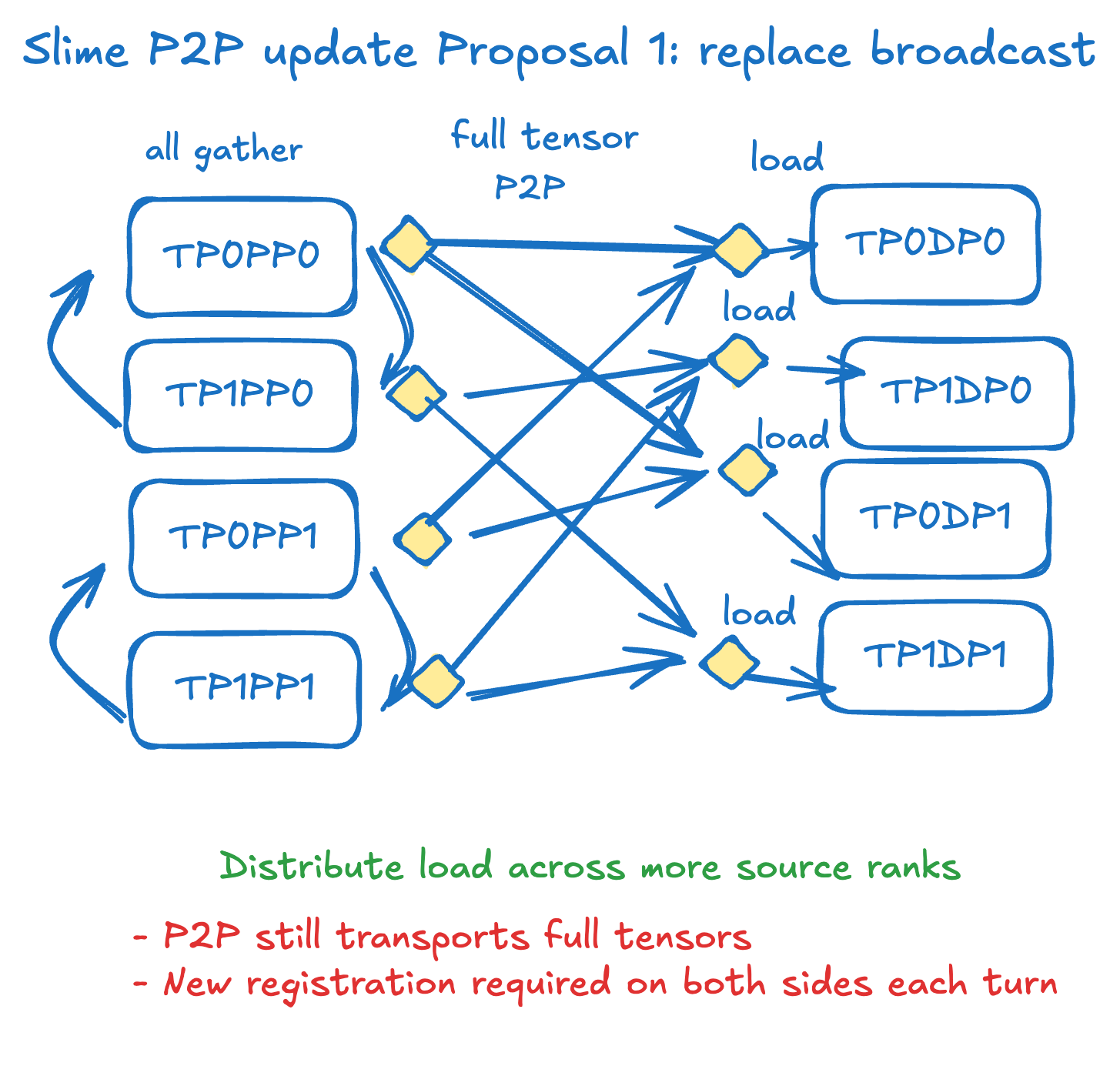
The simplest strategy is to replace the transfer strategy without changing any existing logic. During each bucketed transfer, after the all-gather, transfer the entire HuggingFace weights to the inference side via P2P. This solves inactivity and rigidity, but doesn't solve redundancy — and registering VRAM is expensive, needing re-registration on every transfer.
Design Proposal 2: Build an Inference Engine Replica on the Training Side
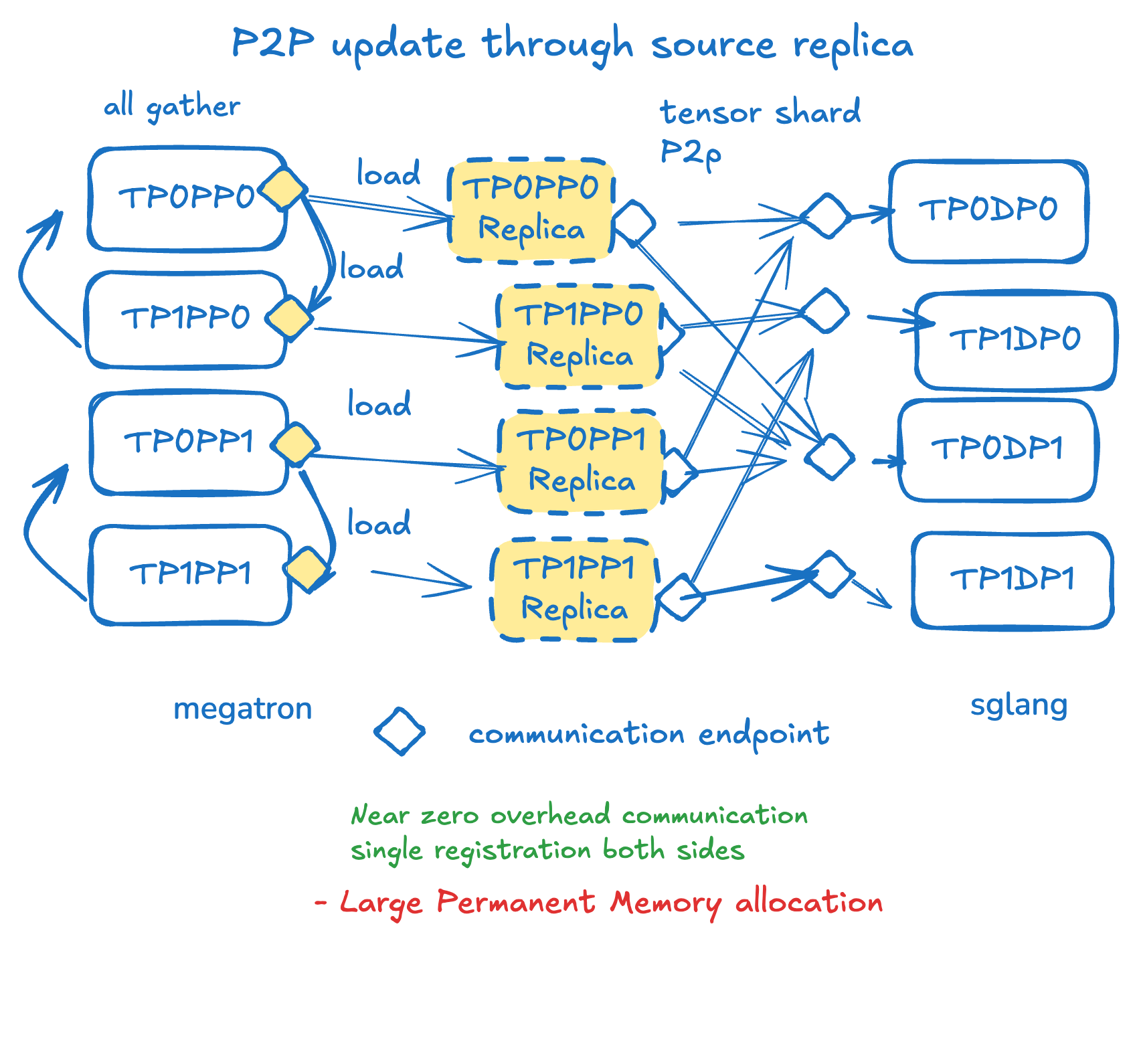
By reusing the remote instance weight info interface and pre-allocating an inference engine model replica on the training side, we only need to transfer the weights the inference engine actually needs, register once, and easily add new engines. This solves all three problems!
model_parallelism_info = engine.get_parallelism_config(rank)
with ParallelismContext(RankParallelismConfig.from_dict(model_parallelism_info)):
model_replica = get_model(
model_config=model_config,
load_config=load_config,
device_config=device_config,
)Training-Inference Mapping
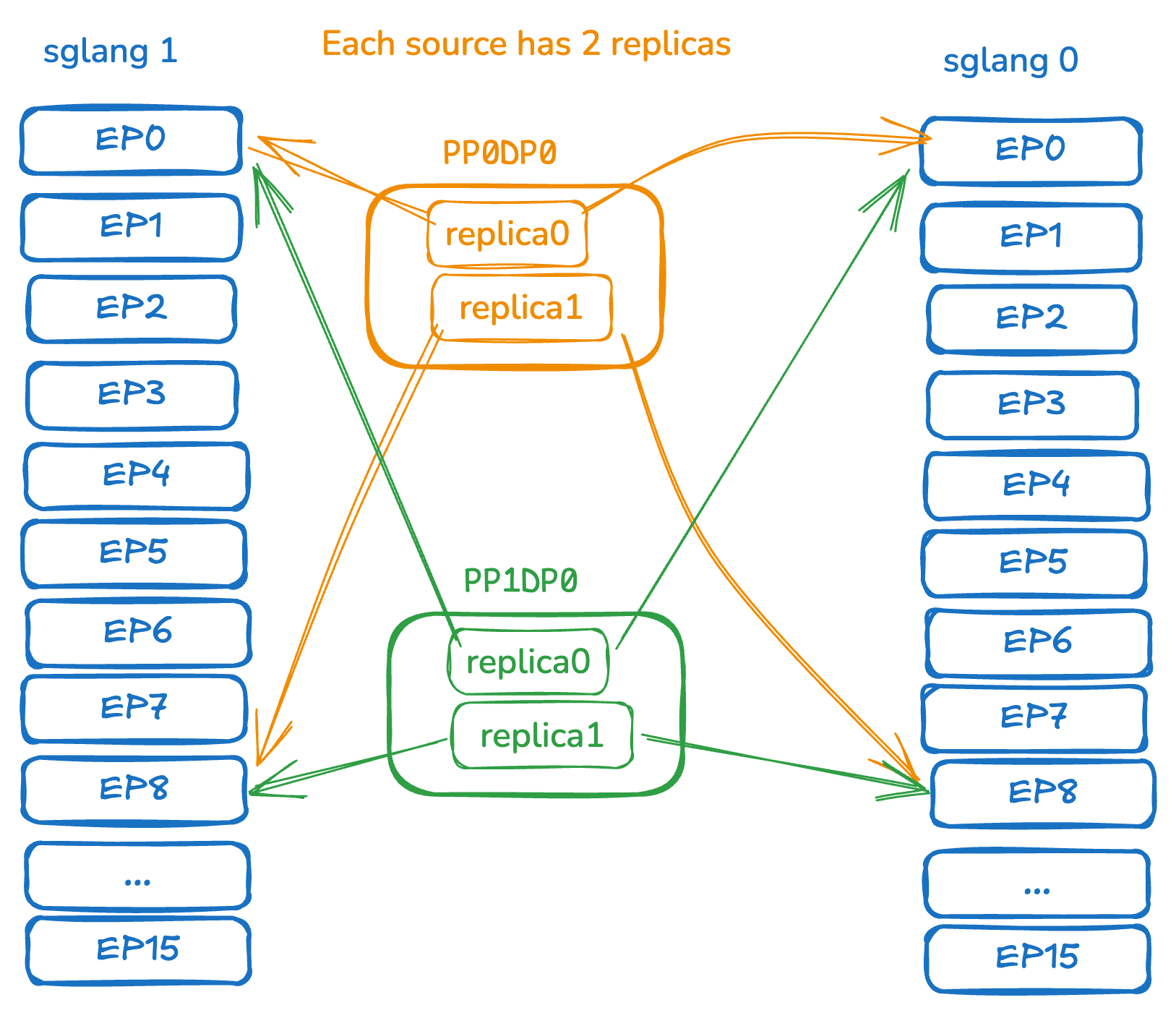
Given: Every inference engine must receive all weights.
Find: How to satisfy this with the minimum number of engine replicas per training node?
Answer: Map each training rank to its target inference engine ranks using load-balanced round-robin assignment.
Exercise: Suppose training pp=4, with 32 training ranks and 2 SGLang engine instances (16 ranks each). How many engine replicas does each training node need?
Answer: Two replicas per training node. After all-gather, each PP group has 8 source ranks mapped to all 32 target ranks via round-robin. On training rank 0, one replica sends to ranks 0 & 16, the other to ranks 1 & 17.
Weight Mapping and Pipeline Updates
We built ParameterMapper in SGLang to independently parse mapping relationships:
sglang_name, shard_id, num_shards, expert_id, num_local_experts = parameter_mapper.map(hf_tensor)Only when all shards and all local experts are fully updated can we send that SGLang weight. Tasks are submitted to a ThreadPool where Transfer Engine releases the GIL.
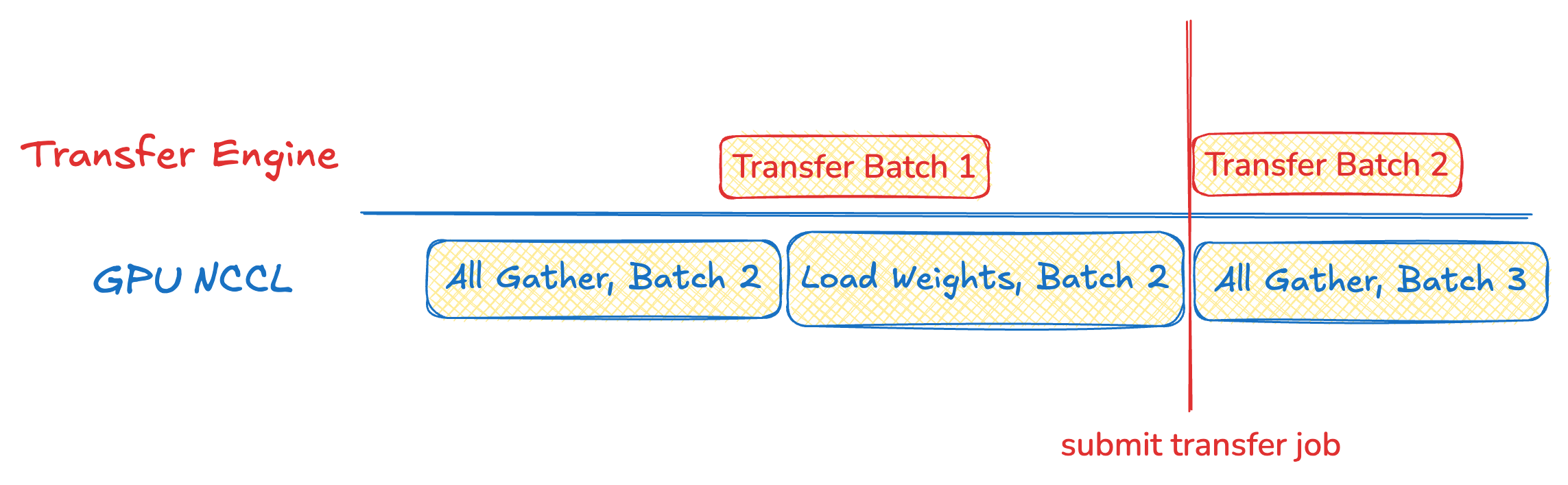
for hf_tensors in all_gather(self.bucketed_update()):
ready_tensors = []
for hf_tensor in hf_tensors:
sglang_name, shard_id, num_shards, expert_id, num_local_experts = parameter_mapper.map(hf_tensor)
ready_tensor.append(self.is_tensor_ready(sglang_name, shard_id, expert_id))
for engine in local_engine_replicas:
engine.load_weight(hf_tensors)
for target_rank in self.get_target_ranks(engine):
submit_transfer(ready_tensor, target_rank, self.thread_pool)First Victory: 235B
After getting it working on Qwen3-4B, we quickly succeeded with Qwen 235B — BF16, 64 GPUs to 64 GPUs, about 3.5 seconds, more than 3x faster than the original NCCL approach. But we realized the extra VRAM consumption would severely impact training efficiency.
VRAM Optimization Attempt 1: Torch Memory Saver
We tried using torch memory saver to keep virtual VRAM addresses unchanged. Unfortunately, Transfer Engine currently cannot support virtual addresses — RDMA registration doesn't support the CUDA VMM API.
VRAM Optimization Attempt 2: Pipeline Optimization
VRAM registration events alone for the 235B model took about 6 seconds, far exceeding the transfer itself — infeasible.
VRAM Optimization Attempt 3: Don't Use VRAM
Why use VRAM as the transfer source at all? Transfer Engine supports both RAM and VRAM. After testing, transfer efficiency was unaffected! The only cost is a D2H transfer to CPU after all-gather. Registration in RAM is also faster since it doesn't go through CUDA.
Future: Huge Pages
The fundamental reason for long GPU registration times is the OS default page size (4KB). Registering 80GB of VRAM produces ~20 million page table entries. Using 32MB page sizes compressed registration time to under 2 seconds.
Memory OOM!
With GLM4.5 (335B, 32B active), 64→64 GPUs, TP=8, EP=8, PP=8 — each node must store an entire inference model's weights! With DP attention, that's (340B + 15B×4) × 2 bytes/tensor → 800GB per node. OOM immediately.
Shared Replicas and Pipeline Updates
Each rank in the SGLang engine has a homogeneous model structure — same tensor sizes and formats, just different values. So all engine replicas on each rank can share the same physical memory (shared replica).
with ParallelismContext(parallelism_config):
model = get_model(
model_config=ModelConfig(model_path),
load_config=load_config,
device_config=DeviceConfig(device="cpu"),
)
if first_engine_rank:
for param in model.parameters():
param.data = param.data.pin_memory()
self._shared_params_dict = dict(model.named_parameters())
self._shared_param_mapper = ParameterMapper.from_model(model)
else:
for name, param in model.named_parameters():
param.data = self._shared_params_dict[name]
We must ensure old transfers complete before loading new weights into shared memory. The first replica's transfer completion is now a prerequisite for continuing the flow.
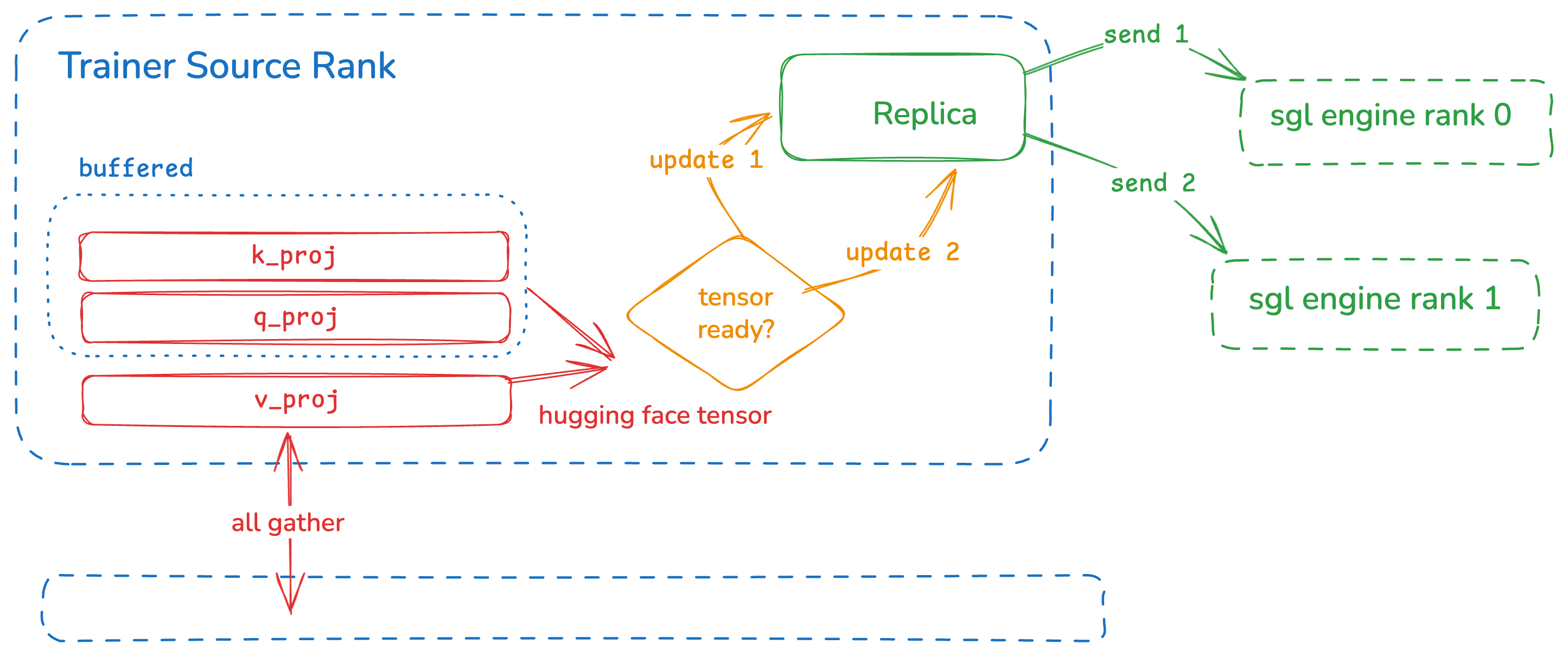
We also need to buffer HuggingFace weights until the corresponding SGLang weight has collected all shards — avoiding premature load_weight calls that would lose needed shard information.
Estimating Transfer Advantages
| Metric | NCCL Broadcast | RDMA P2P |
|---|---|---|
| Training-side ranks in transfer | pp | M |
| Params received per inference rank | ep × P | P |
| Source-side extra buffer | K | K* + P |
| Target-side extra buffer | K | 0 |
- Redundancy → Only transfer parameters the model actually needs
- Inactivity → All training-side ranks participate in transfer
- Flexibility → P2P design; adding a new inference side only requires adding a target
Post-Quantization Processing
In GLM5 and Kimi K2 experiments, check weight equal passed but logprobs didn't match. Loading has two parts: load_weight() and post_load_weights() (post-processing for layout, quantization, and hardware optimizations like DeepSeek MLA generating w_kc, w_vc weights). We force skip post_load_weights on the training side and call it again on the inference side via a new SGLang API.
Complete Update Steps
Before Execution:
| Step | Description |
|---|---|
| get_remote_instance_transfer_engine_info | Get inference-side weight registration info |
| get_parallelism_info | Get inference-side parallelism info |
| build_transfer_plan | Get training-inference mapping |
| create_engine_replica | Create training-side engine replicas |
During Updates:
| Step | Description |
|---|---|
| pause_and_register_engine | Pause inference, register replica weight memory |
| update_weight | Bucketed weight update (non-expert and expert) |
| post_process_weights | Weight post-processing |
| update_weight_version | Update weight version |
| continue_generation | Resume inference |
Experimental Results
Transfer speeds on H100 8-GPU hosts with InfiniBand. Averages of ten updates (excluding the first), including the entire update flow.
| Model | Params | Training Config | Inference Config | NCCL (ms) | RDMA (ms) | Δ |
|---|---|---|---|---|---|---|
| GLM-Z1-9B | 9B | TP=2,PP=1,CP=2,EP=1, 1N | TP=4,EP=1, 1N | 694.6 | 707.1 | +1.8% |
| Moonlight-16B | 16B(3B) | TP=2,PP=1,EP=8, 1N | TP=8,EP=8, 1N | 1,482 | 1,073 | -27.6% |
| GLM-4.7-9B-Flash | 30B(3B) | TP=4,PP=1,EP=8, 1N | TP=4,EP=4, 1N | 2,509 | 4,229 | +68.6% |
| Qwen3-30B | 30B(3B) | TP=4,PP=1,EP=8, 2N | TP=8,EP=8, 2N | 2,670 | 2,160 | -19.1% |
| GLM-4.5-Air | 106B(12B) | TP=1,PP=4,EP=8, 4N | TP=8,EP=8, 4N | 5,001 | 2,637 | -47.3% |
| Qwen3-235B | 235B(22B) | TP=4,PP=4,CP=2,EP=16, 8N | TP=32,EP=32, 8N | 10,754 | 3,162 | -70.6% |
| GLM-5 | 744B(40B) | TP=4,PP=8,CP=2,EP=16, 16N | TP=64,EP=64, 16N | 58,302 | 8,480 | -85.5% |
| Kimi-K2-FP8 | 1T(64B) | TP=8,PP=8,CP=4,EP=32, 32N | TP=32,EP=32, 32N | 53,279 | 7,227 | -86.4% |
P2P transfer shows the most significant gains in large MoE architectures with high EP on the inference side. The sparser the model, the better the results. Support for AMD GPUs will be added soon.
Core code: Miles P2P | SGLang PR | SGLang Issue | Slime Docs